Android Developer should know these Data Structures for Next Interview
- Authors
- Name
- Amit Shekhar
- Published on




I am Amit Shekhar, I have taught and mentored many developers, and their efforts landed them high-paying tech jobs, helped many tech companies in solving their unique problems, and created many open-source libraries being used by top companies. I am passionate about sharing knowledge through open-source, blogs, and videos.
Join my program and get high paying tech job: amitshekhar.me
Before we start, I would like to mention that, I have released a video playlist to help you crack the Android Interview: Check out Android Interview Questions and Answers.
Bad programmers worry about the code. Good programmers worry about data structures and their relationships — Linus Torvalds
This is very true. That is why every employer looks for a good amount of understanding of Data Structures in the candidates while interviewing. This holds true for Android Developers also.
In this blog, we are going to cover all the data structures which are a must for any Android developer when it comes to cracking the interview and knowledge. Although there are many more to learn, we will cover the most used and the most frequently asked in Android Interview.
What is a Data Structure?
A data structure is a data organization, management, and storage format that enables efficient access and modification.
More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data.
For example, we have some data which has, person name “ABC” and age 25. Here “ABC” is of String data type and 25 is of an integer data type.
We can organize this data as a record like a User record, which will have both the user’s name and age in it. Now we can collect and store user’s records in a file or database as a data structure.
Now, let’s look into the most used and frequently asked data structures in Android.
Most used and most asked data structures in Android
- Array
- Linked List
- Hash Table
- Stack
- Queue
- Tree
- Graph
Let’s look into all of these data structures one by one in detail.
Array
Arrays are the most used and the easiest data structure that is used for storing the same kind of data. An array is a collection of similar items that are stored in contiguous memory locations.
For example, if you are storing the marks of 10 students then you can do this by creating 10 integer variables for each student and you can store the marks in these variables. But you have to manage 10 different variables here, which is a very difficult task because if in the future you have to store marks of 1000 students, then you have to create 1000 variables if you are following this approach.
So, we can use arrays for this purpose. All you need to do is just create an array named “marks” of size 10 or 1000 or anything else and then store the marks in that array.
NOTE: In almost all programming languages, we use the 0-based indexing i.e. the indexing of the array will start from 0 and goes until n-1 where “n” is the size of the array.

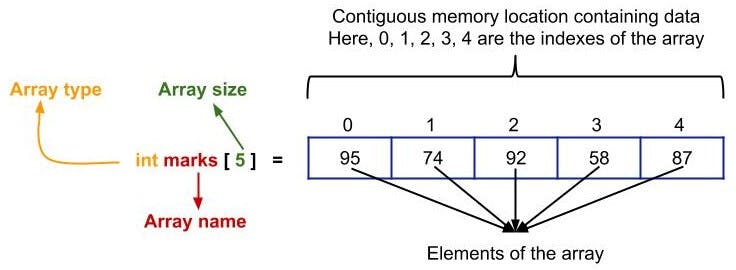
You can access the elements of the array with the help of its indexes:
marks[0] // to access the 1st element i.e. element at index 0
marks[2] // to access the 3rd element i.e. element at index 2
marks[4] // to access the 5th element i.e. element at index 4
Some of the basic operations on Arrays:
- Insertion: Insert a given element at a particular index of the array
- Deletion: Delete a given element from the array
- Searching: Search for a particular element in the array
- Updation: Update an element of an array at a particular index
- Traversing: Print or traverse the whole array
Few questions to try out related to the array:
- Max and Min in an array
- Reverse an array
- Minimum Absolute Difference in an Array
Linked List
A linked list is almost similar to an array i.e. it is also a linear data structure to store the same kind of data. Here, the data is not stored in a continuous manner. The data stored in the linked list is in the form of nodes and each node can be connected to another node with the help of some pointers or reference to the next node.
So, there are two parts of a node in a linked list i.e. the data part and the pointer or reference part. The data part stores the data of the node, while the pointer or reference part stores the address of the next node(if any).


The above image is an example of the singly Linked list i.e. here we have the address of the next node only. There is one more linked list called the “Doubly linked list” where the address of the previous and next node is held by any node. Apart from these two types of a linked list, we have a “Circular linked list” also.
Here in the above image, the “Head” is pointing to the first node of the linked list and the last node of the linked list is pointing to “Null” i.e. there is no node present after that node.
Some of the basic operations on Linked List:
- Insertion: Here, you have to insert the node in the linked list. You have to insert the node at the end of the linked list or at the starting of the linked list or anywhere in between the linked list.
- Deletion: In the deletion operation, you have to delete the node either from the front i.e. you have to delete the head node or you have to delete any node from the linked list.
- Searching: You will be given an element and you have to search for that element in the Linked List.
- Traversing: Traverse the whole linked list to get each and every element of the linked list.
Few questions to try out related to the Linked List:
- Reverse a linked list from position m to n
- Detect and Remove loop in a Linked List
- Remove nth node from the end of the Linked List
- Remove Duplicates from Sorted List
Hash Table
Hash Table is a type of Data Structure that is used to store the data in the form of “Key-Value” pair. You will have some value or data and based on that data you will generate one key and with the help of that key, you will store the value in the Hash Table. If the input is uniformly distributed then the Hash Table will perform the insertion, deletion, and searching operation in O(1) time.
The process of generating the key and storing the data based on that key is called “Hashing”. To generate the key from the data, we need one function known as “Hash Function”. The Hash Function will take the data as an input and give the key as the output.
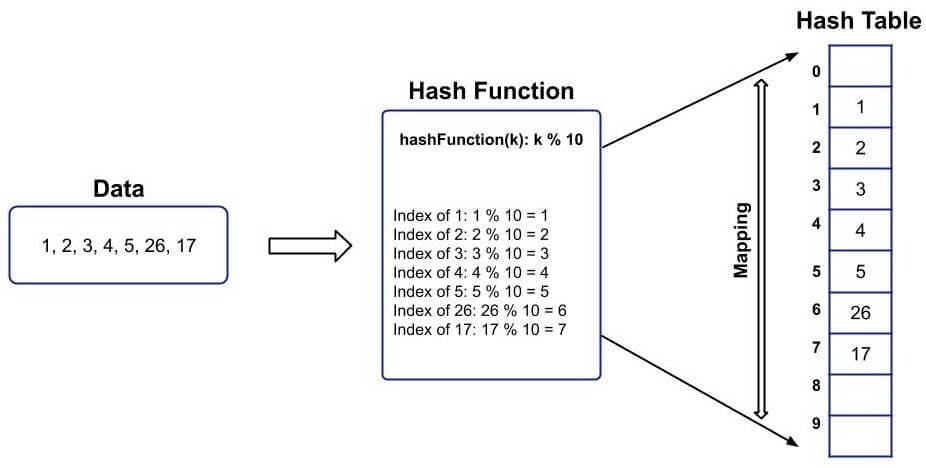
For example, If the data to be stored is: 1, 2, 3, 4, 5, 26, 17 and the hash function used is:
hashFunction(k): k % 10
And the data will be stored in the Hash Table in the following way:

Points to think of while using Hash Table:
- The Hash Function should be such that the keys generated are uniformly distributed.
- The size of the Hash Table is dependent on the Hash Function. So, the choice of Hash Function should be done perfectly.
- In the case of a collision in the Hash Table, apply proper collision handling technique.
Few questions to try out related to Hash Table:
- Longest Consecutive Sequence
- Valid Anagram
- Largest subarray with 0 sum
- First Unique Character in a String
Stack
A Stack is a linear Data Structure that uses the Last In First Out order(LIFO) i.e. the element inserted last will be popped out first. For example, if you are putting one book over others and continue this process for 50 books, then the topmost book will be fetched first. Here you can notice that the topmost book is that book which is placed at the end or which is recently placed.
In Stack, we have a “Top” variable that denotes the top of the Stack. This is necessary because all the operation of the stack is done with the help of the “Top” variable.
Following is an example of a Stack:

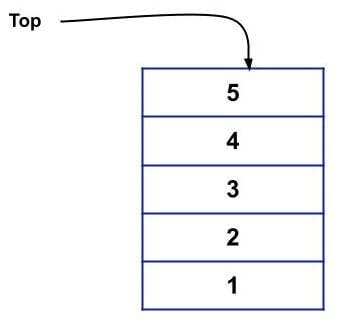
If you want to delete elements from the above Stack, then 5 will be deleted first, followed by 4, 3, 2, and 1.
Some of the basic operations on Stack:
- Push(): Push is used to insert an element at the top of the stack.
- Pop(): Pop is used to delete an element from the top of the stack.
- Top: Top is used to denote the top element of the stack.
Few questions to try out related to Stack:
- Check for balanced parentheses in an expression
- Reverse a stack using recursion
- Implement Queue using stacks
- Sort a stack using another stack
Queue
A Queue is a linear Data Structure that uses the First In First Out(FIFO) order i.e. the element coming first in the Queue will be deleted first from the Queue. For example, while standing in a queue for ticket booking, the person coming first will book the ticket first and the new person coming to book ticket have to stand at the end of the Queue.
In Queue, we have “Front” and “Rear”. The Front is used to point to the front element of the queue while the Rear is used to point to the rear element of the Queue.
Following is an example of a Queue:

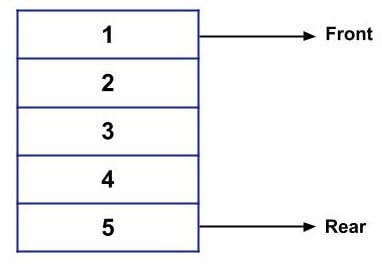
So, if you want to delete the elements from the above queue, then 1 will be deleted first, followed by 2, 3, 4, and 5.
Similarly, if you want to insert an element in the above queue then it will be inserted from the Rear and not from the Front.
Some of the basic operations on Queue:
- Enqueue(): Enqueue is used to insert an element at the end of the Queue.
- Dequeue(): Dequeue is used to delete an element from the front of the Queue.
- Front: It is used to denote the front element of the Queue.
- Rear: It is used to denote the Rear element of the Queue.
Few questions to try out related to Queue:
- Implement Queue using stacks
- Reverse first k elements of a queue
- LRU cache implementation
Tree
A Tree is a non-linear, hierarchical Data Structure that is used to store data in the form of nodes. Here, we have node and all the nodes are connected with each other with the help of edges that are drawn between them. A parent node can have no child or one child or more than one child. But the child node can’t have more than one parent.
Following is a simple example of Tree:

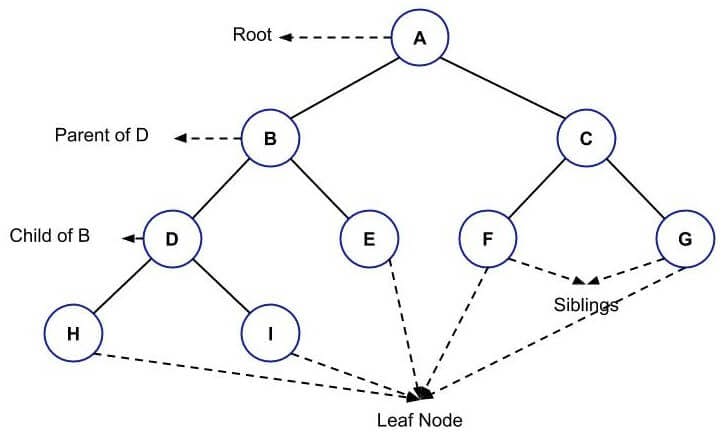
Some of the terms related to trees are:
- Root: Root is the node that is present at the top of the tree. There can be only one root of a particular tree.
- Parent: All the nodes having at least one child is called the parent node.
- Child: The node below the parent node is called the child node of the parent node.
- Leaf: The node having zero children is called the leaf node.
Some of the types of trees are:
- General Tree
- Binary Tree
- Binary Search Tree
- AVL Tree
- Red-Black Tree
- N-ary Tree
Few questions to try out related to Tree:
- Find height on a Binary Tree
- All Nodes Distance K in Binary Tree
- K-th largest element in BST
- Merge Two BST
Graph
A Graph is similar to that of trees i.e. it is also a non-linear data structure that stores the data in the form of nodes and all the nodes are connected with each other with the help of edges. The difference between trees and graphs is that there is a cycle in a Graph but there is no such cycle in case of a Tree.
A Graph consists of a finite set of nodes and a finite set of edges that are responsible for connecting the nodes.
Following is an example of a Graph:

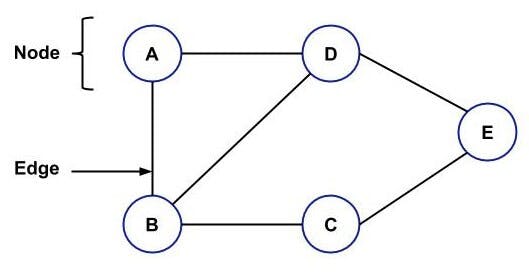
Following are the types of Graph:
- Directed Graph: Here the edges will point to some node i.e. you will have an arrow pointing towards a node from a node.
- Undirected Graph: Here no arrow is there in between the nodes. The above example is an example of an undirected graph.
Some of the common Graph traversal techniques are:
- Depth-First Search(DFS)
- Breadth-First Search(BFS)
Few questions to try out related to Graph:
- Word ladder problem
- Knight on Chessboard
- Number of Islands
- Check loop in array according to given constraints
If you need any help during your interview preparation, do not hesitate to reach out to me.
Prepare yourself for Android Interview: Android Interview Questions
That's it for now.
Thanks
You can connect with me on: